基于多模态语言模型的低延迟端到端自动驾驶模型
摘要
针对当前自动驾驶中在自动驾驶领域中,人类驾驶数据集缺乏可解释性,多模态大型语言模型可解释性强但实时性低的,基于模仿学习的端到端模型可解释性和实时性之间无法权衡的问题,本文提出了一种利用多模态大语言模型对自动驾驶数据集进行决策原因和关键物体的标注,并通过多任务学习决策原因和关键目标,为决策过程提供直观解释的同时,避免了实时推理阶段直接使用大模型推理带来的推理延迟,从而在保证实时性的情况下增加了可解释性。本研究的工作为自动驾驶领域的数据标注和决策提供了新的思路,并在实验中取得了显著的效果。
关键词:自动驾驶;多模态大语言模型;模仿学习;多任务学习
引言
随着人工智能技术的快速发展,自动驾驶技术已经成为了当下科技领域最具活力和前瞻性的研究热点之一。在自动驾驶领域,基于模仿学习的端到端模型因其简单的结构与复杂场景下强大的泛化性能而受到关注。受限于其原理,模仿学习的输出往往难以达到或超越直接模仿的专家系统的水平。因此,模仿学习的数据集的质量对模型的性能有着至关重要的影响。
目前被广泛使用的专家数据包括基于规则的专家算法采集的数据、基于强化学习的专家算法采集的数据以及人类驾驶专家采集的数据。基于规则的专家算法则需详尽定义各类规则,违背了端到端模型简洁的设计初衷,且限制了端到端算法在复杂场景下的泛化性能;基于强化学习的专家算法虽然在决策能力上表现出色,但其生成的策略与人类驾驶习惯差异显著。相比之下,使用人类专家的驾驶数据进行学习可以有效避免上述问题,其驾驶习惯与人类相符,无需编写具体规则,且在复杂场景中展示出较好的泛化能力,从而显著提升模型的实际应用价值。然而,这种方法通常缺乏决策过程的可解释性,且人类行为存在个体差异,决策具有一定的不一致性,从而引起安全顾虑和法律问题,甚至危及乘客和行人的安全。
近年来,随着多模态大型语言模型的发展[1,2,3],使得通用人工智能领域取得了显著进展。这些模型在包括自动驾驶在内的多个领域展现出优秀的性能,并且具备较高的可解释性。然而,大语言模型在实时推理任务中表现出较慢的处理速度和较低的实时性,在需要即时响应的应用场景中难以直接使用。
综上所述,人类驾驶数据集在可解释性和决策一致性方面仍存在不足。尽管多模态大型语言模型在可解释性方面表现优异且能有效识别决策的不一致性,但其在自动驾驶领域的直接应用仍受限于处理速度慢和实时性低的显著缺点。因此,在自动驾驶领域中的可解释性和实时性之间的权衡问题亟待解决。
鉴于此,本研究针对基于模仿学习的端到端算法,在数据标注与决策算法上展开研究。本文的主要贡献如下:
- 针对端到端模型在学习人类驾驶数据集过程中可解释性不足的问题,提出了一种利用多模态大语言模型对自动驾驶数据集进行决策原因和关键物体的标注方法,并通过多任务学习决策原因和关键目标,为决策过程提供直观解释的同时,提高模型的性能;
- 针对大语言模型在自动驾驶中直接推理时实时性较低的问题,提出了在数据集处理中使用大语言模型对驾驶数据进行详尽的标注,避免了实时推理阶段的延迟,从而在保证实时性的情况下增加了可解释性。
相关工作
模仿学习在自动驾驶中的应用
随着现代人工智能技术的快速发展,端到端学习方法已广泛应用于汽车自动驾驶技术中。与难以收敛且与人类驾驶习惯有显著差异的强化学习(Reinforcement Learning, RL)[4,5,6]相比,模仿学习(Imitation Learning, IL)[7,8]通过直接利用专家数据进行监督学习,不需要像强化学习那样从头开始探索。这种方法不仅收敛速度快,而且可以获得较为稳定和可预测的行为输出。
随着自动驾驶模仿学习的发展,方法从最初的直接模仿动作,逐步过渡到更复杂的轨迹模仿和多任务学习。CIL[9]使用自车元信息、高级指令与图像编码器,对控制动作进行直接预测。在此基础上,CILRS[10]随后被提出,进一步引入了目标速度预测。然而,这种基于直接控制的方法通常具有更高的车辆碰撞率。Transfuser[11]及其变体使用一个简单的GRU来自回归预测行驶路径点,有效降低了碰撞率。Interfuser[12]则通过多任务学习将安全相关输出与路径规划输出分离,进一步提升了模型的性能同时,提高了模型的可解释性。LCDiff则进一步引入了BEV预测模块,提升了模型在复杂场景下的泛化性能。
在模仿学习中,选择正确的数据集对于算法的性能和可行性至关重要。文献[13,14]使用了具有全局信息的强化学习专家行驶数据作为数据集进行训练,展示了在处理复杂交通环境时的高效性能,然而其生成的策略与人类驾驶习惯差异显著,在一些复杂情况下通常会做出一些不可解释的危险行为。文献[11,12,15]使用了规则专家的驾驶数据作为数据集进行训练,证明了这种方法在保持行为一致性和规则遵循方面的有效性。尽管如此,这种方法通常缺乏应对未预见情况的灵活性,且需要编写具体的规则。使用人类专家的驾驶数据进行学习可以生成与人类驾驶习惯相符的行为,无需编写具体规则,在复杂场景中也有出较好的泛化能力,从而提高模型的实际应用价值。然而,这种方法通常缺乏决策过程的可解释性,且人类行为存在个体差异,决策具有一定的不一致性。
多模态大语言模型在自动驾驶中的应用
近年来多模态大语言模型等通用人工智能技术发展迅速,研究者开始探索将这些先进模型应用于自动驾驶的可能性。这些模型在提高决策过程的可解释性和减少违规行为方面表现出色。LMDrive[16]使用自然语言指令作为输入,结合多传感器数据,通过多模态大语言模型生成驾驶决策,在输出轨迹与控制动作的同时,提供了决策原因的解释,增强了模型的可解释性和透明度。
然而,大语言模型在实时推理任务中表现出较慢的处理速度和较低的实时性,在真实驾驶场景中难以直接使用。为了解决实时性问题,DriveVLM[17]提出了一种双系统快慢机制,通过使用传统的端到端模型进行快速推理,再通过大语言模型进行慢速推理,一定程度上缓解了实时性问题,提高了系统的响应速度和实用性。尽管有所改进,这种双系统机制在处理高度动态和复杂的驾驶场景时仍显示出性能和实时性的局限,特别是在需要同时考虑多个突发因素和紧急响应的情况下。
方法与实现
本文提出了一种新颖的基于多任务学习的端到端自动驾驶模型,并结合了多模态大语言模型来标注人类驾驶数据集中的决策原因和关键物体,以提高模型的性能和可解释性。本方法主要包括多模态大语言模型标注与多任务模仿学习两个部分。如图1所示,本模型在训练前,先通过多模态大语言模型对人类驾驶数据集进行全面的标注。针对包含刹车、大幅转向等关键驾驶行为的数据帧X_t,使用X_(t-3)到X_t的连续帧中的图像、雷达、交通参与者信息与控制作为输入,得出驾驶意图I_t与关键物体O_t的标注。在训练与推理阶段,将多模态信息输入感知编码器得到融合特征$F_t$,将$F_t$输入到决策模型中,在预测航点$W_t$-$W_{t+3}$的同时,预测所需驾驶意图$I_t$与关键物体$O_t$,以多任务输出的方式提高模型的性能与可解释性。通过预测的航点$W_t$-$W_{t+3}$与当前速度$V_t$、当前方向角$\theta_t$,分别对速度与方向角进行PID控制,得出最终的控制动作预测:转向$\delta_t$、油门$T_t$与刹车$B_t$。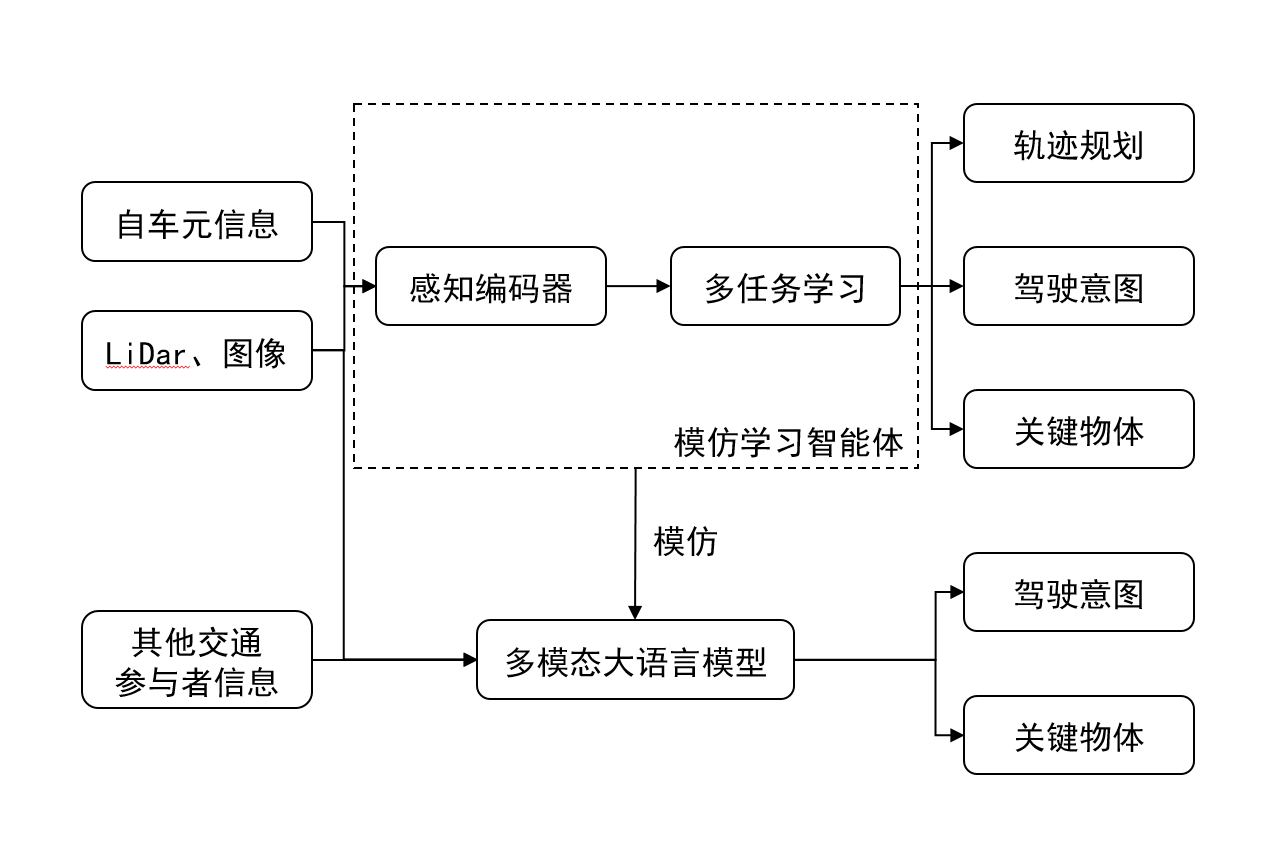
自动驾驶模型建模
自动驾驶模型的目标是在复杂的城市环境中,在各种交通状况、道路类型和不可预测元素(如行人过街和各类天气)的情况下,使车辆能够自主、安全、高效地行驶。模型从起点A行驶至终点B,通过全球导航卫星系统(GNSS)坐标$TP_0$至$TP_n$指引路径。在行驶中的每个时刻t,车辆可以获得当前位置$P_t$、当前速度$V_t$、当前方向角$\theta_t$,并根据不同的传感器配置,可以获得图像数据$I_t$、激光雷达数据$L_t$等多模态信息。基于这些输入,端到端自动驾驶模型$Model(.)$的任务是输出车辆的控制动作,基础模型设计如下:
$$\delta_t, T_t, B_t = Model(TP_{0-n}, P_{0-t}, V_{0-t}, \theta_{0-t}, I_{0-t}, L_{0-t})$$
其中,$\delta_t$、$T_t$、$B_t$分别表示车辆在时刻t的转向、油门和刹车控制动作。$Model(.)$表示一个端到端的自动驾驶模型,输入为导航点、车辆位置、速度、方向角、图像和激光雷达数据,输出为车辆的控制动作。自动驾驶模型的任务就是通过处理这些多模态输入,解读复杂的环境信息,并在不违反交通规则的前提下,做出合理的决策,以实现车辆的自主行驶。
此外,为了使模型能够充分理解驾驶环境,本研究设计了一个多任务学习框架,以提高模型的性能和可解释性。驾驶意图$I_t$与关键物体$O_t$被设定为多任务学习的目标,同时环境感知任务,例如BEV特征$BEV_t$,也被列为多任务学习目标。总体的模型设计如下:
$$\delta_t, T_t, B_t, I_t, O_t, BEV_t = Model(TP_{0-n}, P_{0-t}, V_{0-t}, \theta_{0-t}, I_{0-t}, L_{0-t})$$
数据采集与多模态大语言模型标注
为了支撑这些多任务学习目标,本研究需要一个精确标注的数据集。因此,在端到端自动驾驶领域被广泛采用的CARLA[18]模拟器被选为数据采集工具,该模拟器能够提供一个逼真的动态闭环世界。数据收集包括两个阶段:
- 人类专家在CARLA中根据导航点驾驶,并收集传感器数据和控制信号;
- 使用多模态大语言模型对包含刹车、大幅转向等关键驾驶行为的数据进行驾驶意图与关键物体的标注。
人类专家在CARLA模拟器中进行人工驾驶,并以2Hz的频率进行数据采集,共采集了2.2万帧的驾驶数据。每一帧数据包括了车辆的当前位置、速度、方向角、导航点、图像和激光雷达的传感器数据,油门、刹车与转向的控制动作,以及附近交通参与者位置与BEV特征的高级信息。为了增强收集数据集的多样性,采集过程共使用了14种天气,涵盖了早晨、中午、傍晚等不同时间段,以及晴天、阴天、雨天等不同天气条件。传感器配置上使用了三个RGB摄像头(左、前、右)和一个激光雷达,侧面摄像头的角度为60°。为了验证模型的泛化能力,LAV[19]路线中的Town02与Town05在采集过程中被有意避免,并被设置为测试场景。
本研究选用Qwen-VL[3]作为多模态大语言模型,对数据集进行详细标注来提高模型的性能和解释性。针对包含刹车、大幅转向等关键驾驶行为的数据帧,需要对其进行驾驶意图与关键物体的标注,整体流程如图2所示,首先将连续的四帧的的图像序列作为输入,并通过文本的方式输入当前帧的控制信息,得到驾驶意图输出与其对应描述。驾驶意图被分为17类,包括但不限于加速、减速、转向、变道、绕行、轻微位置调整和等待。在得到驾驶意图后,继续通过多模态大语言模型的上下文记忆能力,标注出影响决策的关键物体。关键物体被定义为在当前帧中对驾驶意图产生重要影响的物体,如前方车辆、行人、交通标志、信号灯等。由于大语言模型对数值计算的支持较弱,本研究通过输入当前帧的交通参与者相对位置信息的方式,让大语言模型通过选择而非计算来标注出关键物体。
多任务学习框架
为了提高模型的性能和可解释性的同时,保证模型的实时性,本研究设计了一个多任务学习框架,该框架针对由大语言模型完成标注的驾驶意图与关键物体进行学习。主任务设置为直接影响驾驶行为的航点预测任务,而辅助任务包括环境感知任务、驾驶意图预测以及关键物体预测。这些辅助任务旨在促进模型对驾驶环境的理解,从而提高模型的性能,同时提供直观的决策解释。
如图3所示,多任务学习的目标包括环境感知任务、航点预测、驾驶意图预测和关键物体预测。为了避免[12]中提出的捷径问题,并确保车辆始终保持在车道线内,该框架使用了一个标准的Transformer解码器来处理感知特征$F_t$。一部分经处理的嵌入特征被输入到门控循环网络(GRU)中,以预测未来航点的位置$W_t$-$W_{t+3}$。与此同时,另一部分嵌入特征被输入到安全解释器中,用于预测驾驶意图$I_t$与关键物体$O_t$。在感知任务中,感知解码器根据感知特征$F_t$对BEV特征$BEV_t$进行预测。
预测的航点$W_t$到$W_{t+3}$,结合当前速度$V_t$和方向角$\theta_t$,被进一步处理以输出对车辆的控制值。这些数据输入到两个独立的PID控制器,分别调节速度和方向,输出最终的控制动作预测:转向$\delta_t$、油门$T_t$与刹车$B_t$。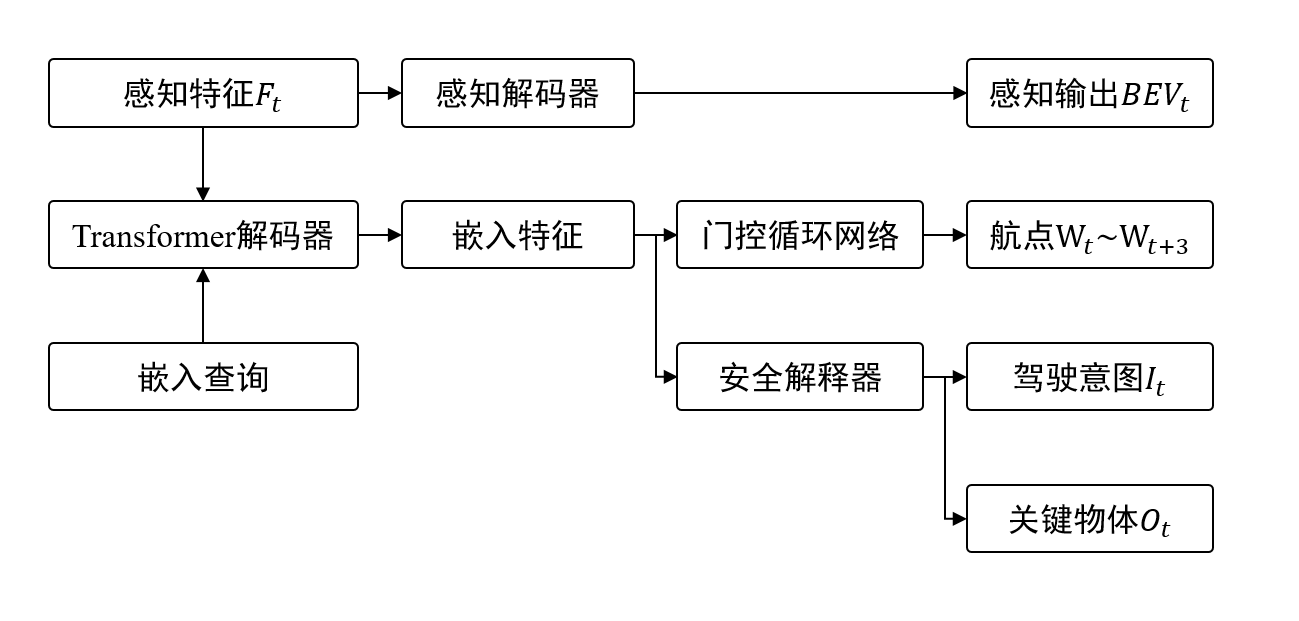
实验
评估指标
在自动驾驶任务中,由于对模型的评估不能依赖简单的准确率或偏离率指标,因此,本研究采用了Carla模拟器来进行闭环模拟驾驶。为了测试自动驾驶系统的稳健性和反应能力,设计了一系列复杂的城市环境,包括多车道道路、复杂的路口、以及偶尔出现的突发交通状况。模型的评估采用了几个关键的指标:路线完成度(Route Completion,RC),该指标衡量车辆成功完成路线的百分比;违规分数(Infraction Score,IS),该指标随着车辆违反交通规则的次数增加而降低;综合驾驶分数(Driving Score,DS),即RC与IS的乘积,用于综合评价模型的性能。这些指标涵盖了模型完成路线的能力与遵守交通规则的表现,是Carla闭环模拟中评价自动驾驶模型性能的重要指标。
实验设置
实验环境使用0.9.10.1版本的Carla模拟器,并使用Carla leaderboard来评估模型的性能。模型在两组不同的路线与14种天气条件上进行测试,包括Longest6[11]路线与LAV[]路线。其中Longest6路线所涉及的城镇在训练时被使用,而LAV路线的城镇则未在训练中使用,以验证模型的泛化能力。
感知编码器上,我们分别使用了LCDiff所提出的BEV感知模型和Transfuser的感知模块,以验证本研究提出的多任务学习框架的性能。LCDiff使用了扩散模型,并使用LiDar数据通过ControlNet结构来引导BEV的生成,从而能够输出高精度的BEV特征。Transfuser的感知模块使用Transformer在不同尺度上对图像与LiDar进行融合,并采用自注意力机制来增强全局环境理解。
模型性能对比
在LCDiff和Transfuser外,本研究的多任务学习框架还与其他几个最先进的自动驾驶模型进行了比较,包括LAV与Interfuser。LAV通过使用模型能观测到的所有车辆的数据来进行数据增强,从而提高了模型的泛化能力。Interfuser通过多任务学习将安全相关输出与路径规划输出分离,进一步提升了模型的性能。值得注意的是,被比较的模型均使用了规则专家或强化学习专家的驾驶数据集进行训练,而本研究的模型则使用了人类专家的驾驶数据集经过多模态大语言模型标注后进行训练。
表1. 在Longest6路线上的实验结果*
| 方法 | DS↑ | RC↑ | IS↑ |
|---|---|---|---|
| LAV | 58.3±1.1 | 83.2±1.3 | 0.68±0.02 |
| Interfuser | 46.8±5.6 | 74.3±1.0 | 0.63±0.07 |
| Transfuser | 46.6±6.2 | 92.9±1.2 | 0.50±0.06 |
| LCDiff | 53.3±2.6 | 94.9±0.7 | 0.56±0.02 |
| Ours(Transfuer-based) | 52.7±2.7 | 95.6±1.5 | 0.55±0.02 |
| Ours(LCDiff-based) | 64.3±2.5 | 97.6±0.9 | 0.66±0.02 |
*3次实验的平均值与标准差
从表1中可以看出,本研究提出的多任务学习框架在训练城镇Longest6路线上的表现优于其他几个最先进的自动驾驶模型。以Transfuser为感知模块的多任务学习框架在DS、RC和IS上比原模型提高了13.1%、2.9%和10.0%,而以LCDiff为感知模块的多任务学习框架在DS、RC和IS上则比原模型提高了14.8%、2.8%和12.1%。这表明本研究提出的辅助任务驾驶意图预测与关键物体预测,能够有效提高模型遵守交通规则的能力,同时也增强了模型在复杂环境下的导航准确性。在使用LCDiff感知模块的框架中,得益于高精度BEV特征作为辅助任务,模型在IS上取得了很大的提升。
表2. 在LAV路线上的实验结果*
| 方法 | DS↑ | RC↑ | IS↑ |
|---|---|---|---|
| LAV | 60.4±2.5 | 94.5±1.1 | 0.64±0.02 |
| Interfuser | 38.2±1.5 | 62.7±3.6 | 0.61±0.04 |
| Transfuser | 39.1±9.2 | 84.2±6.8 | 0.46±0.06 |
| LCDiff | 55.6±3.0 | 98.1±1.0 | 0.57±0.03 |
| Ours(Transfuer-based) | 50.3±2.2 | 85.9±2.0 | 0.59±0.02 |
| Ours(LCDiff-based) | 63.9±3.1 | 98.4±0.6 | 0.65±0.03 |
*3次实验的平均值与标准差
从表2中可以看出,本研究提出的多任务学习框架在未见过的验证城镇LAV路线上同样表现出色。基于Transfuser的变体在DS、RC和IS上比原模型提高了28.6%、2.0%和28.3%,而基于LCDiff的变体在DS、RC和IS上则比原模型提高了14.9%、0.4%和14.0%。由于LAV路线的城镇未在训练中使用,Transfuser的基础模型在IS上表现较差,比较容易违反交通规则,而本研究提出的多任务学习框架使其在IS上取得了很大的提升。在使用LCDiff感知模块的框架中,由于其泛化能力较Transfuser更强,基础模型已有较高的RC,然而在IS上,多任务学习框架的引入仍然使其取得了进一步的提升。
针对自动驾驶模型的实时性,本研究在不同模型上进行了推理时间的对比。实验环境中,CPU为AMD Ryzen 9 7950x, GPU为NVIDIA RTX 3090,内存为64GB,实验系统为Ubuntu 22.04。实验路线选用了Longest6路线,实验取每一帧的平均推理时间作为对比指标。除了Transfuser和LCDiff外,LMDrive[16]作为直接使用多模态大语言模型的代表也被选为对比对象,使用了其提供的基于LLaVA-v1.5-7B微调的模型。实验结果如表3所示。
表3. 单帧平均推理时长
| 方法 | 推理时长(ms)↓ | DS↑ | RC↑ | IS↑ |
|---|---|---|---|---|
| Transfuser | 44ms | 46.6 | 92.9 | 0.50 |
| LCDiff | 159ms | 53.3 | 94.9 | 0.56 |
| LMDrive | 1769ms | 44.5 | 51.1 | 0.87 |
| Ours(Transfuer-based) | 47ms | 52.7 | 95.6 | 0.55 |
| Ours(LCDiff-based) | 166ms | 64.3 | 97.6 | 0.66 |
从表3中可以看出,本研究提出的多任务学习框架在推理时间上对比基础模型Transfuser和LCDiff相当,且在性能上均有所提升。LCDiff的推理时间较长,主要是因为高精度BEV特征的生成与其扩散模型的架构限制。对比起直接使用多模态大语言模型的LMDrive,多任务学习框架在推理时间上有较大的优势。值得注意的是,LMDrive在路线完成度(RC)上表现不佳,主要原因在于该模型使用大语言模型直接进行数值预测,这种方法在处理具体的导航任务时可能不如基于回归的方法精确。然而,在违规分数IS上,LMDrive的表现较好,其遵守交通规则的能力明显优于其他模型,这表明大语言模型在预见潜在违规行为方面具有很大的优势。
消融实验
针对基于模仿学习的端到端自动驾驶模型,数据集的选择对模型训练和性能具有重要影响。为了深入研究这一影响,本研究进行了消融实验,通过比较规则专家数据集与人类专家数据集对模型的影响,探讨了这些数据集在模仿学习中的作用及其对模型性能的具体影响。实验路线选用了Longest6路线,针对规则专家数据集,其标签中的驾驶意图与关键物体是由专家算法经过规则判断后得出的,而人类专家数据集则是由人类专家驾驶员在CARLA模拟器中进行人工驾驶后得到的,其驾驶意图与关键物体的标注则是通过多模态大语言模型完成的。训练数据量均为2.2万帧,实验结果如表4所示。
| 方法 | 数据集 | DS↑ | RC↑ | IS↑ |
|---|---|---|---|---|
| Ours(Transfuer-based) | 规则专家 | 49.7±2.2 | 93.6±0.8 | 0.53±0.02 |
| Ours(Transfuer-based) | 人类专家 | 52.7±2.7 | 95.6±1.5 | 0.55±0.02 |
| Ours(LCDiff-based) | 规则专家 | 59.4±2.0 | 95.5±0.8 | 0.62±0.02 |
| Ours(LCDiff-based) | 人类专家 | 64.3±2.5 | 97.6±0.9 | 0.66±0.02 |
从表4中可以看出,无论是基于Transfuser还是LCDiff的多任务学习框架,使用人类专家数据集进行训练均优于使用规则专家数据集。这表明人类专家数据集在模仿学习中具有更高的价值。在Transfuser的基础模型上,使用人类专家数据集训练的多任务学习框架在DS、RC和IS上比规则专家数据集训练的模型提高了6.1%、2.1%和3.9%。在LCDiff的基础模型上,使用人类专家数据集训练的多任务学习框架在DS、RC和IS上比规则专家数据集训练的模型提高了7.8%、1.8%和6.0%。使用人类驾驶数据集进行训练,模型能够更好地理解人类驾驶习惯,特别是可以减少在复杂情况下的违规行为,从而同时提高路线完成度和遵守交通规则的能力。
针对多任务学习框架的性能,本研究进行了消融实验,通过比较多任务学习的引入对模型性能的影响,探讨了多任务学习框架在自动驾驶模型中的作用。模型均使用人类专家数据集进行训练,实验路线选用了Longest6路线。消融实验中,多任务学习框架的辅助任务包括驾驶意图预测与关键物体预测,而主任务为航点预测任务。LCDiff本身包含的BEV感知任务被保留,实验结果如表5所示。
| 方法 | 多任务学习 | DS↑ | RC↑ | IS↑ |
|---|---|---|---|---|
| Transfuer | × | 49.4±3.6 | 94.5±1.1 | 0.52±0.03 |
| Ours(Transfuer-based) | √ | 52.7±2.7 | 95.6±1.5 | 0.55±0.02 |
| LCDiff | × | 56.1±2.3 | 96.4±0.6 | 0.58±0.02 |
| Ours(LCDiff-based) | √ | 64.3±2.5 | 97.6±0.9 | 0.66±0.02 |
从表5中可以看出,本研究提出的多任务学习框架在模型性能上表现出色。在Transfuer的基础模型上,多任务学习框架在DS、RC和IS上比原模型提高了6.7%、1.1%和5.5%。在LCDiff的基础模型上,多任务学习框架在DS、RC和IS上比原模型提高了11.0%、1.2%和9.7%。本研究提出的多任务学习在减少违规行为方面表现出色,能够有效提高模型的性能。值得注意的是,LCDiff本身已经包含了高精BEV感知任务,多任务学习框架的引入使其在IS上取得了很大的提升。
从表5中可以看出,本研究提出的多任务学习框架在模型性能上表现出色。在Transfuer的基础模型上,多任务学习框架在DS、RC和IS上比原模型提高了6.7%、1.1%和5.5%。在LCDiff的基础模型上,多任务学习框架在DS、RC和IS上比原模型提高11.0%、1.2%和9.7%。本研究提出的多任务学习在减少违规行为方面表现出色,能够有效提高模型的性能。值得注意的是,LCDiff本身已经包含了高精度BEV感知任务,其与驾驶意图预测与关键物体预测相结合的多任务学习框架更进一步提高了模型在IS上的表现。
结束语
本研究针对当前自动驾驶中在自动驾驶领域中,人类驾驶数据集缺乏可解释性,多模态大型语言模型可解释性强但实时性低的,基于模仿学习的端到端模型可解释性和实时性之间无法权衡的问题,提出了一种利用多模态大语言模型对自动驾驶数据集进行决策原因和关键物体的标注,并通过多任务学习决策原因和关键目标,为决策过程提供直观解释的同时,避免了实时推理阶段直接使用大模型推理带来的推理延迟,从而在保证实时性的情况下增加了可解释性。实验结果表明,本研究提出的多任务学习框架在多个指标上均超越了其他端到端的基准模型,相比于直接使用大模型推理的方法,本研究提出的多任务学习框架在推理时间上具有较大优势。此外,本研究还通过消融实验验证了人类驾驶数据集在模仿学习中的重要性,以及多任务学习框架在自动驾驶模型中的作用。
本研究在以下方面还存在改进空间:1. 本研究的研究场景仅限于城市环境,未考虑高速公路、乡村道路等其他场景,未来可以进一步扩展研究场景;2. 由于多模态大语言模型的成本较高,本研究的数据集规模较小,未来可以进一步扩大数据集规模与场景多样性,以进一步提高模型的泛化能力。总的来说,本研究的方法为自动驾驶模型的可解释性和实时性提供了新的思路,对于提高自动驾驶模型的性能和可解释性具有重要意义。
参考文献
[1] Liu H, Li C, Wu Q, et al. Visual instruction tuning[J]. Advances in neural information processing systems, 2024, 36.
[2] Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
[3] Bai J, Bai S, Yang S, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond[J]. 2023.
[4] Toromanoff M, Wirbel E, Moutarde F. End-to-end model-free reinforcement learning for urban driving using implicit affordances[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 7153-7162.
[5] Jin Y L, Ji Z Y, Zeng D, et al. VWP: An efficient DRL-based autonomous driving model[J]. IEEE Transactions on Multimedia, 2022.
[6] Prakash A, Chitta K, Geiger A. Multi-modal fusion transformer for end-to-end autonomous driving[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 7077-7087.
[7] POMERLEAU D A.ALVINN:an autonomous land vehicle in a neural network[C]/Proceedings of the 1st International Conference on Neural Information Processing Systems.Cambridge,MA,USA:[s.n.],1988:305-313.
[8] BOJARSKI M,DELTESTA D,DWORAKOWSKI D,et al.End to End Learning for Self-Driving Cars[EB/OL].(2016-04-25) [2022-12-20].http://arxiv.org/abs/1604.07316.
[9] Codevilla F, Müller M, López A, et al. End-to-end driving via conditional imitation learning[C]//2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018: 4693-4700.
[10] Codevilla F, Santana E, López A M, et al. Exploring the limitations of behavior cloning for autonomous driving[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9329-9338.
[11] Chitta K, Prakash A, Jaeger B, et al. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
[12] Shao H, Wang L, Chen R, et al. Safety-enhanced autonomous driving using interpretable sensor fusion transformer[C]//Conference on Robot Learning. PMLR, 2023: 726-737.
[13] Wu P, Jia X, Chen L, et al. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline[J]. Advances in Neural Information Processing Systems, 2022, 35: 6119-6132.
[14] Zhang Z, Liniger A, Dai D, et al. End-to-end urban driving by imitating a reinforcement learning coach[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 15222-15232.
[15] Jaeger B, Chitta K, Geiger A. Hidden biases of end-to-end driving models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 8240-8249.
[16] Shao H, Hu Y, Wang L, et al. Lmdrive: Closed-loop end-to-end driving with large language models[J]. arXiv preprint arXiv:2312.07488, 2023.
[17] Tian X, Gu J, Li B, et al. DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models[J]. arXiv preprint arXiv:2402.12289, 2024.
[18] Dosovitskiy A, Ros G, Codevilla F, et al. CARLA: An open urban driving simulator[C]//Conference on robot learning. PMLR, 2017: 1-16.
[19] Chen D, Krähenbühl P. Learning from all vehicles[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 17222-17231.